
Welcome back to our ongoing series!
The last few months have taken us deep into one of the biggest challenges and greatest opportunities in today’s drug development industry: the fast-growing data deluge flooding today’s life sciences organizations.
Every year that flood gets petabytes deeper, leaving many drug developers swamped with massive amounts of unstructured, fragmented, and ultimately unusable information. As we’ve seen in this series, the vast majority of that data will remain forever stranded in file cabinets, SharePoints, and inboxes – and it’s costing the life sciences industry a fortune in development delays, regulatory setbacks, and missed opportunities.
Now if you’ve been following the first three chapters in our series, I suspect I know what’s on your mind: “Yash, this all makes sense, I see why drug developers are drowning in seas of unmanaged data, and I can clearly identify the operational challenges we could address by tackling our unstructured CMC knowledge… but how does that actually work?”
Well! I’m glad you stayed tuned for Chapter 4, because this is where rubber hits road. So let’s dive straight in, and have a look at how structured data principles can help drug developers achieve a long-sought operational holy grail: automation.
The CMC lifecycle is more complex than ever
Taking a step back, let’s start by revisiting the CMC lifecycle. It’s become dauntingly complicated as more and more cell-and-gene modalities enter the global pipeline.
For today’s product candidates, the journey to validated processes still follows the familiar pathway of design, to qualification, to continuous validation (CPV). But in parallel, product programs must also plan for an increasingly complex array of other development and risk management activities:
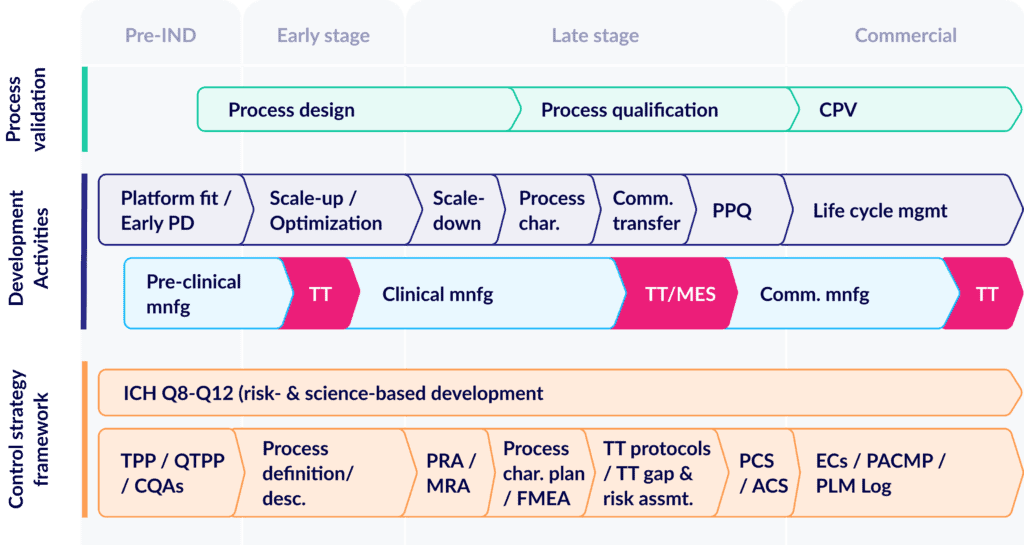
As manufacturing processes go through their “formal” development steps, drug sponsors and contract manufacturers must navigate a series of related development tasks from fit-finding, to process characterization, to PPQ. All while also managing multiple tech transfers needed to scale up production and deliver a high-quality supply of clinical trial material.
At the same time, drug developers also need to create a detailed risk management framework that demonstrates robust process understanding, process capability, and continually evolving mitigation. And it’s this last step that frequently leaves drug developers grasping for real control and understanding of their risks.
A truly comprehensive control strategy should span every single facet of the manufacturing process – whether it’s a raw material, unit operation, or finished product. Yet all too often, sponsors struggle to keep that strategy in step with their core development activities. Risk assessments are often performed retroactively, and based on tacit knowledge instead of direct data tying precise process capabilities to specified risks.
Why? As we saw in the first 3 chapters of our series, the source of this disconnect often comes back to the way drug developers manage their CMC data. Or don’t.
After all, how is a CMC contributor supposed to show control of a specific parameter when the CQAs are on the SharePoint in a PDF labeled “RX1075tpp_rev 3_updated_Nicksversion_R2” and the last official risk analysis is on the desktop of someone’s old computer? How do you establish deep understanding and comprehensive control of risks without equally holistic and integrated process knowledge?
This is just one of the areas where we see both an acute need for better data structures and the profound value of establishing them. And that begs the first big question we need to answer: which structures are the right ones for a CMC data framework?
Luckily, that one’s easy.
ICH Q8 can be the cornerstone of CMC workflow automation
When it comes to planning a comprehensive CMC data structure, the ICH guidelines are an optimal place to start. They define the essential quality and compliance parameters for the pharmaceutical development process.
For a risk-based control strategy, we can zoom in immediately at ICH Q8. It provides a perfect working example of how structured data principles can be applied to core CMC information – by creating a digital QTPP.
Let’s take a closer look at how.
ICH Q8 specifies that a control strategy should:
- Describe and justify how in-process controls and the controls of input materials (drug substance and excipients), intermediates (in-process materials), container closure system, and drug products contribute to the final product quality.
- Show that those controls are based on product, formulation, and process understanding.
- Include (at a minimum) control of critical process parameters and material attributes.
So far, so familiar – but when it comes that vital second bullet, often easier said than done. I’m looking at you, RX1075tpp_rev 3_updated_Nicksversion_R2.pdf.
Demonstrating “product, formulation, and process understanding” requires robust, multidimensional risk assessments (ICH Q8 section 2.3) that clearly “[identify] which material attributes and process parameters potentially have an effect on product CQAs,” defined via the QTPP. And that’s notoriously hard to do when those material attributes, process parameters, CQAs – all your product and process information, really – are scattered across documents, departments, and memory banks.
That’s why it’s no surprise that lots of drug development organizations struggle to build the understanding required by ICH Q8, much less the control strategy grounded in that understanding. And it’s why the QTPP – the foundation of an effective, comprehensive control strategy – is the perfect place to start structuring CMC data.
That resource isn’t just a PDF that everyone links to on SharePoint (or at least it shouldn’t be!). It contains all the essential building blocks of a risk-based approach to complying with the safety and efficacy requirements of product quality. The first place to start: Freeing those blocks from the document and turning them into foundational data points.
A 3-step approach to building a digital QTPP
In my recent feature on FAIR data principles – co-authored with my colleagues Paul Denny-Gouldson, Sujeegar Jeevanandam, and John F. Conway – we laid out a simple but transformative way to turn CMC resources into multidimensional datasets. The ultimate goal: liberating data from a document so it can be structured, linked, contextualized, and used for bigger purposes.
The ICH defines a QTPP as a “prospective summary of the quality characteristics of a drug product that ideally will be achieved to ensure the desired quality, taking into account safety and efficacy of the drug product.” To extract those characteristics in usable form, we can follow these three steps:

Step 1: Atomize
Break down the QTPP into individual nodes of information categorized by product (requirements and attributes), process (operational steps and variables), or plant (assets and materials).
Step 2: Assemble
Group those data points into nodes of related information using industry-relevant taxonomies like ICH, QBD, or GMP. In the case of a QTPP, let the ICH be your guide.
Step 3: Link
Identify associations and define relationships between the nodes based on industry-relevant ontologies such as risk, process capability, and control strategy.
Once you’ve completed those steps, you’ll find that you no longer have a traditional QTPP: a document that provides the only indexable reference for ALL the information it contains. Instead, you have an array of easily findable, readily accessible, fully interoperable, and reusable data points – the raw material of a modern data framework for your whole CMC program.
Let’s take a quick look at how each step works for a QTPP.
Step 1: Atomizing a QTPP
Typically, a QTPP is managed as a comprehensive, controlled document. What many drug developers don’t realize, though, is that this “document” is really a collection of separate elements – primarily product quality attributes.
So, to begin the process of digitizing the QTPP, start by atomizing the information it contains by converting the document into separate data objects. Here’s an example:
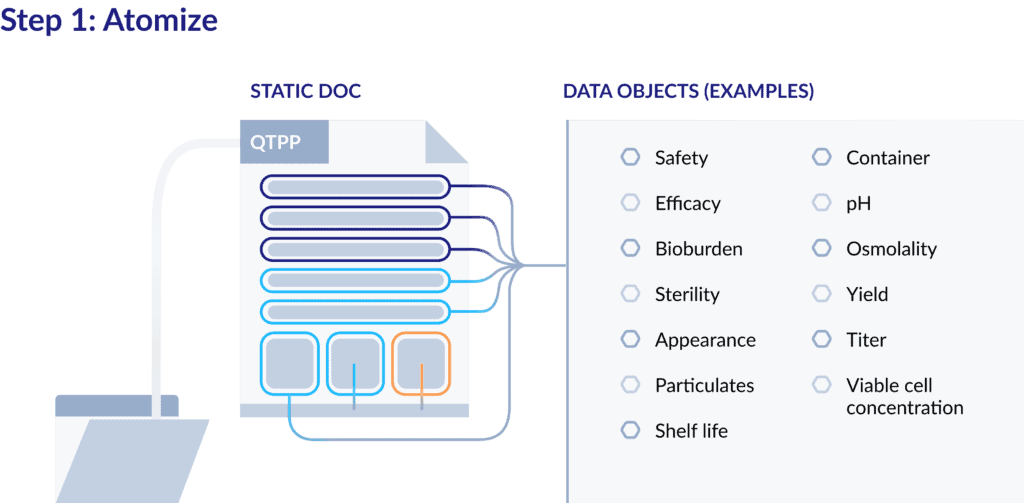
Once the elements of the QTPP are defined separately, they can be managed and tracked that way as well. Your team can then index the content of QTPP, rather than just the document.
Once you take individual control of these points, you can also manage and update them individually as well – instead of iterating entire documents every time, no matter how small the change. Create a canonical version of a data point, and updating it once updates it everywhere. And there never needs to be a RX1075tpp_rev 3_updated_Nicksversion_R3.pdf.
Step 2: Assembling QTPP data objects
Once you’ve atomized the data points in your QTPP, you can easily sort this information into a coherent structure by categorizing the elements based on language of ICH, QbD, and GMP.
The example below shows how typical QTPP components can be grouped as general attributes, quality attributes, and performance attributes.
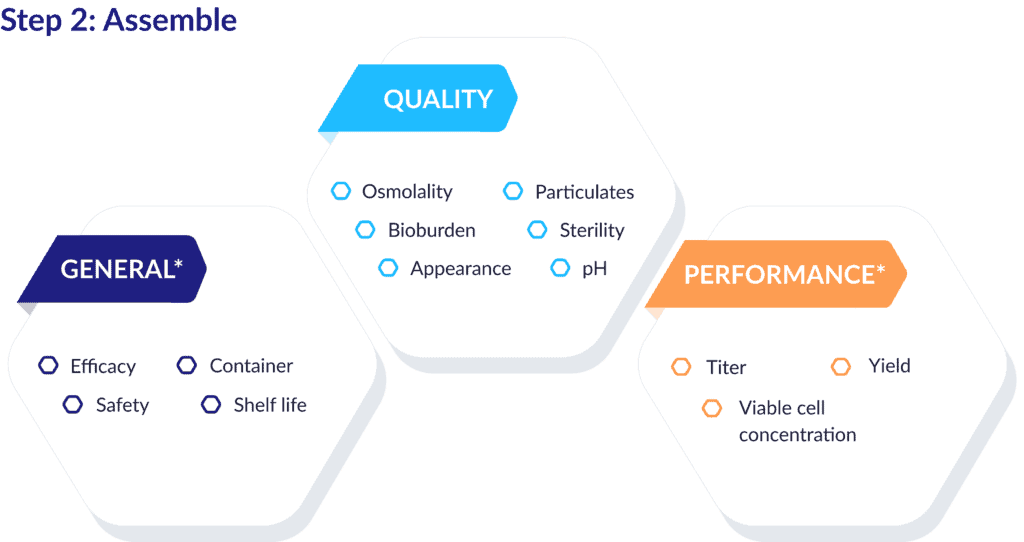
Bonus: Categorizing elements this way gives you a rich set of metadata you can apply to each one, such as risk assessments, acceptance criteria, and control methods. The labeling schema you create is the critical bridge between this organizing step and the next one – where you connect these data points in ways that help the real magic happen.
Step 3: Linking QTPP data elements
After atomizing and assembling the discrete components of the QTPP, the true power of this process begins to emerge.
Now, you can link those records, create contextualizing relationships between data points, assess and trace causality, and ultimately provide justification for decisions made throughout the development process. Here’s what that can look like for a production-ready QTPP:
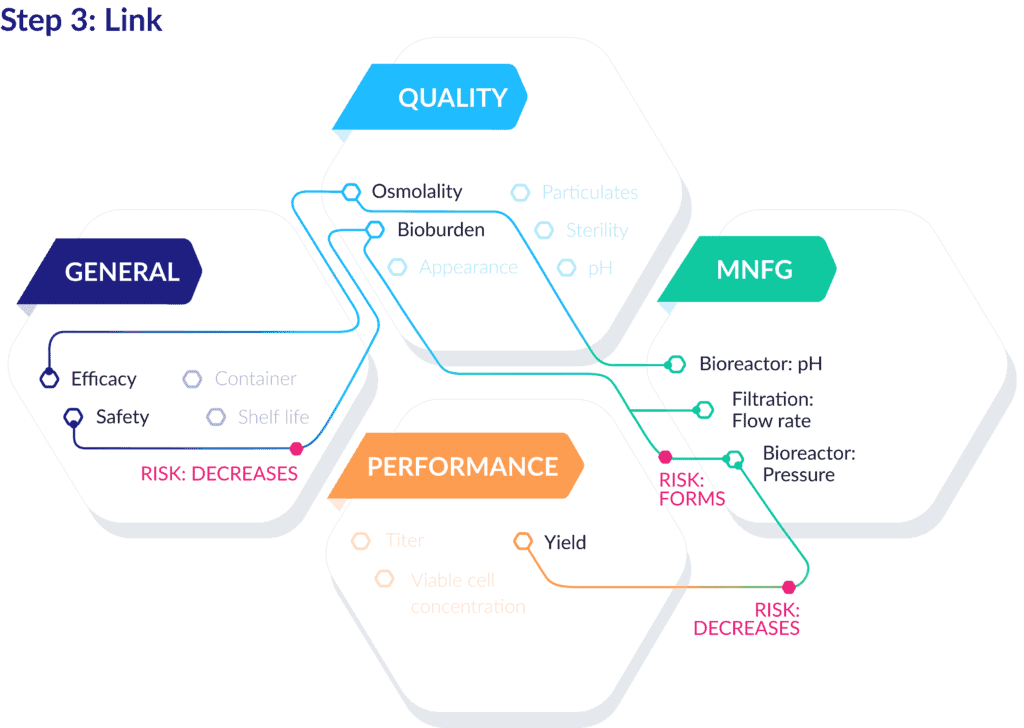
As you can see, these links can extend far beyond the core QTPP components and connect with attributes and parameters of many other processes, units, equipment, and materials. You can also further dimensionalize these linked data points by connecting associate risks, effects, controls, and more.
And while we’re focused on ICH for the purpose of digitizing a QTPP, there are many other potential ontologies that can be applied to other essential datasets. ICH, QbD, and GMP all provide valuable concepts that can be translated into metadata.
See it in action: Transforming auditor inquiries into instant CMC insights
Okay, so now we’ve translated your QTPP into a structured set of individually linkable, manageable, and leverageable data points – and put them at the heart of a multidimensional CMC data framework. What does it look like when you put that structure to work?
Fast forward to your next PAI. Your inspector has questions about your CMC program (don’t they always?). And they want those answers to be supported by data that shows strong governance and consistent integrity.
You know how that exchange will typically go:
- Gather all your CMC documents in one room (and hope you haven’t missed any)
- Get the inspector and all your SMEs together in a different room (and hope you’ve included all the right brains and memories)
- Shuffle documents back and forth between both rooms until all the inspector’s questions have been answered
It’s… time-consuming. There’s lots of frantic flipping through binders and last-minute file collation. There are always spreadsheets that have to be reformatted so they can fit on the biggest piece of paper you can print them on.
And then there’s the data supporting your answers to the inspector’s questions. Breadcrumbing conclusions to analyses and raw data can be a painful process with no guarantee of success – and also a high risk of a 483 if the inspector throws a data integrity flag on that play.
But with all that data integrated into a structured framework, answering tough questions can be as simple as a click – one that connects to a seamless chain of data custody all the way back to the raw data.
Here are just few examples of the kinds of questions you can instantly answer with your CMC data in FAIR format:
- “Can I see a process flow map of your manufacturing process?” Absolutely. That’s a cinch when your entire process is digitally connected from start to finish, down to the most nuanced parameter.
- “Can I see a list of your CQAs and their control methods?” Easy. Your CQAs will be stored and managed in one central location, and directly linked to specific controls for each attribute.
- “Which process parameters affect this particular CQA? Are they critical?” Simple. Just pull up that specific CQA and click the associated CPP(s).
- “Can you show me the FMEA for unit operation X in your process?” No problem. The record for Unit Op X connects directly to every FMEA report it influences.
- “What’s the control strategy for sterility for your drug product fill-finish?” Click. There are all the steps, parameters, and risks associated with sterility.
- “What’s your process capability for Bioburden as an in-process control for sterility?” Click again. There are all process parameters related to bioburden.
Atomize, assemble, and link the data in your QTPP – and that’s just one key CMC document – and demonstrating compliance can truly be that easy and fast. All it takes is consistent application of structured data principles. Implement from the ground up, and answering those common questions can be as simple as click, show, “approved.”
Of course, this is just what you can do by digitizing a single cornerstone CMC resource. What happens when you scale that up to an entire CMC program?
Just ask one of our QbDVision power users!
Check out how top drug developers are putting structured data principles to work
If you caught any of the great content from last year’s Digital CMC Summit, you’ve seen how seriously many life science organizations are now taking their data governance and integrity initiatives. For many, it’s already starting to pay off in powerful ways.
And it’s not just streamlined audits and inspections. With a comprehensive Digital CMC framework in place, top drug developers are discovering that they can unlock a range of exciting new capabilities – from automated reporting, to instant generation of key regulatory documents, to accelerated tech transfers.
Here are just a few examples:
Xeris Biopharma has turned to digital CMC tools to streamline risk assessments, systematize regulatory submissions, and keep CMC off the critical path for tech transfers. VP CMC Peter Knauer calls it an “astounding change to the way we do things.”
Sanofi and Bayer have both used cutting-edge digital CMC solutions to connect their entire CMC ecosystem, a step that’s helping them safeguard data integrity, save development time, and maximize quality.
A major regional generics manufacturer turned to QbDVision to help them modernize their CMC program, and ultimately helped triple the speed at which they can execute tech transfers.
All of these organizations are already discovering the impact digitization can have on their CMC workflows, and capturing multidimensional value from their investment. Together, they offer some powerful examples of structured data principles at work – and a preview of what other drug developers can achieve with similar initiatives.
One last stop! Don’t miss Chapter 5 of our series
Here in Chapter 4, we’ve just laid out an approach to applying modern data principles in CMC workflows – and shown how many ways that effort can deliver value and accelerate organizational performance. For chapter 5, we’ll look closer at how this same effort can help drug developers prepare for another looming industry shift: digitizing regulatory submissions.
In case you missed Sue Plant’s excellent presentation at the 2023 Digital CMC Summit, now’s the time to stream it. She takes a prescient look at how digital regulatory submissions are poised to shake up the industry, one that beautifully sets the stage for the last chapter in our series.
Until then!
Miss a chapter? Catch up on the whole series:
Chapter 1: Pharma, Biotech, and the data deluge >
Chapter 2: Modernizing the structure and management of drug development data >
Chapter 3: Taking a structured digital approach to CMC data >
GET IN TOUCH
Ready to start automating CMC compliance workflows?
Reach out any time to learn how we can help you build the data foundation you need to transform your regulatory submissions.


























































