
Good rules make good drivers: Why drug development can’t seem to get anywhere with their data
Here’s a thought experiment for you: Imagine what it would be like to drive with no lanes or laws.
Madness, right?
If you’ve been lucky enough to visit some of South Asia’s magnificent, ancient cities, you might say you know exactly what that’s like. Millions of people eventually get from A to B, but the process is… let’s say, more organic than efficient. One way or another, everyone figures out how to make it work. But it’s far from an optimized process.
Even if you’ve never traveled that far, though, you may still know exactly what it’s like to see thousands upon millions of things moving through a space with no rules, no standards, and only the guidance they create for themselves. And you may be all too familiar with the delays, confusion, and inefficiency that that can cause.

If you’re like many drug development professionals, you don’t need to hop on a plane to experience that. You can just crack open your SharePoint.
And with that quick thought experiment, we’re back with the next chapter in our ongoing series on data governance and integrity in the drug development industry. In our kickoff post, we looked at why drug developers are still struggling with the many penalties and handicaps of unstructured data – and why that problem is rapidly intensifying with every fresh exabyte of data they produce. Now, in the second chapter of our story, we’ll look at how our industry can begin to structure its way out of that challenge.
Welcome back!
Tackling the “sum total of arrangements” challenge
As we saw in the first post in this series, pharma and biotech companies often have a sharp gradient between their scientific rigor and their data management discipline. Many are still struggling with information channels so tangled, inconsistent, and choked with heterogeneous files and formats, a Mumbai khaali peeli would feel right at home in them.
But as we also saw, and as we’ll dig into here, effective data governance depends on clear consistent rules – just like drivers need lanes, speed limits, signals, signs, and more. For knowledge and information to move efficiently through a business system, that business needs a similarly robust governance structure for its data.
Which begs the question: what should we look for in that structure? What kind of framework best supports effective governance of drug developers’ unique and uniquely complex data?
In our kickoff post, we looked at why drug developers are still struggling with the many penalties and handicaps of unstructured data – and why that problem is rapidly intensifying with every fresh exabyte of data. Now, in the second chapter of our story, we’ll look at how our industry can begin to structure its way out of that challenge.
It’s a question that our industry has struggled to answer for some time – and sometimes answered in ways that produce as much confusion as clarity.
For example, one common definition of data governance in GMP environments describes it as “The sum total of arrangements to ensure that data, irrespective of the format in which it is generated, recorded, processed, and retained will ensure an attributable, legible, contemporaneous, original, accurate, complete, consistent, enduring, and available record throughout the data lifecycle.”
The intentions are positive and the goals are mandatory… but at the same time, complex ecosystems ultimately demand much more rigorous, precise, and holistic frameworks for navigating them. Imagine if the DMV presented the rules of the road as “the sum total of driving conventions.” Charge your phone, it’s going to take a while for everyone to figure this out!
No, modern drug developers need data structures – rules for the digital roads their data flow through – that are specific, comprehensive, implementation-ready, and mapped to relevant requirements and concepts. But at the same time, they also need to make sure that their digital processes, systems, and frameworks are… well, actually digital.
“We already have a SharePoint”: Getting to the root of a digital divide
Stop me if you’ve heard this before: “We’re a digital-first organization. We’re all on OneDrive.”
Credit where it’s due, spreadsheets, word documents, PDFs, PPTs, and emails are all a small eon ahead of the paper documents that are still all-too-common in our industry – functionally and ecologically. But “rendered with pixels” is still a far cry from true digital information.
Why? Because out of our industry’s three essential information formats – paper documents, electronic documents, and digital data – two share the same base unit. Whether their document lives in manila folders or OneDrive folders, paper- and e___-based systems both have the same inescapable limitation: their default is to index their documents rather than the data within them.
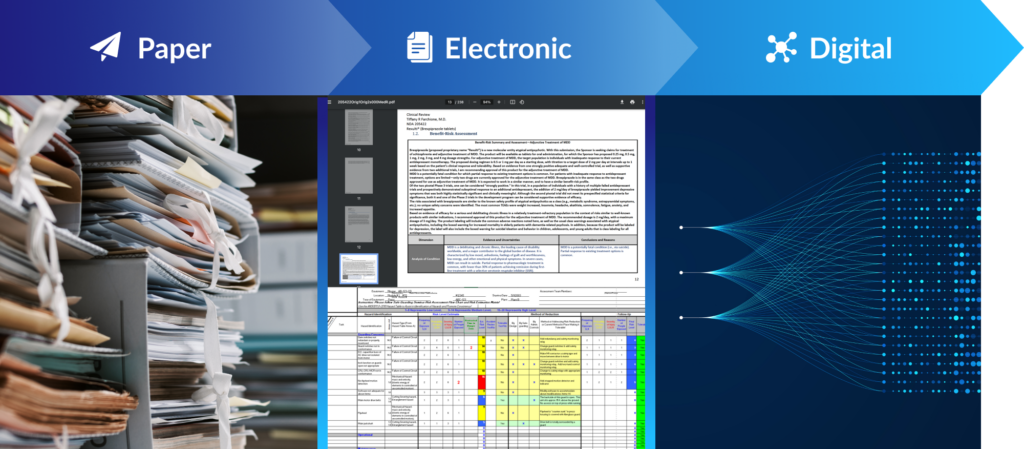
Documents that obscure, restrict, and fragment the data they contain. Documents that put physical and electronic limits on the accessibility and interconnection of all the knowledge they record.
To truly structure and integrate their data, drug developers need to escape not one but both of those limitations. And that starts by atomizing every one of those documents: breaking them down to all the discreet, individual pieces of information they contain. The actual data.
Spreadsheets, word documents, PDFs, PPTs, and emails are all a small eon ahead of the paper documents that are still all-too-common in our industry – functionally and ecologically. But “rendered with pixels” is still far cry from true digital information.
Data that are relational, connectable, and easily referenceable independent of any document. Data that can be linked, integrated, and, yes, structured in ways that facilitate solutions with exponential impact – from powerful visualizations, to automated processes, and streamlined knowledge exchange.
Once we’ve done that work, and documents – paper or electronic – have been fully decomposed into structure-ready data, then we can get back to the big question. What kind of structure should drug developers look for?
Well, that’s a FAIR question indeed. Sorry. Couldn’t resist.
The FAIR data paradigm: A promising framework for drug development data
In my recent collaboration with Paul Denny-Gouldson, Sujeegar Jeevanandam, and John F. Conway, we took a detailed look at why the FAIR data framework is especially attractive and advantageous for drug developers. Simply put, it’s a holistic, comprehensive, and practical paradigm that provides an optimal working schema for CMC data.
That framework has four simple, universal principles. Data should be:

With just those four principles – and a system of identifiers, labels, and metadata that facilitate them – it’s easy to see how data can be created, stored, and used in a format that’s perfectly suited to the many powerful applications we all now associate with modern digital architecture and information systems. Adopting this framework can be an equally powerful first step toward unleashing the power of those technologies within the drug development process.
Is it a replacement for ALCOA+? Absolutely not. In fact, it’s a valuable complement to that established data governance paradigm. While ALCOA precisely defines the target outcome of data integrity efforts – how data should be once data governance processes are applied – FAIR represents functional states and actions that produce those outcomes. Just like targeted health management strategies support target health outcomes, following FAIR principles can help drug developers pave a confident path to the level of data integrity they need to achieve.
|
|
Outcome
|
Functional strategy
|
|---|---|---|
|
Health integrity
|
Weight loss, reduced hypertension, lower cholesterol, lower HbA1c
|
Increased exercise, stress reduction, diet adaptation, insulin therapy
|
|
Data integrity
|
Attributable, Legible, Contemporaneous, Original, Accurate, +Complete, +Traceable
|
Unifying data paradigm (like FAIR), rich (meta)data with industry-relevant taxonomies & ontologies, vertically integrated knowledge base with structured foundation, digital (not electronic) technology that supports automated compliance, organizational commitment to modern data management principles
|
For more on how the FAIR paradigm can be applied to drug development data, I eagerly invite you to explore my collaborative post with Paul, Sujeegar, and John. Suffice it here to say that these four principles represent an optimal framework for drug development data across a wide range of domains and processes – from process development, to risk analyses, to tech transfer and beyond. They can be a powerful tool for establishing a robust and consistent structure across an organization’s data resources, starting from the most discreet base unit of data.
That’s fabulous for the data, though. But what about the people who create and manage it?
Building a “data quality pyramid” that supports consistent data principle implementation
As any scientist or engineer can tell you, data doesn’t simply appear – in a FAIR framework or any other. Data is a generated product, the output of countless processes, experiments, assays, analyses and more.
And for drug developers – for businesses in any industry, really – that means that implementation of any data governance strategy has to start with the people who create and manage what goes into that ecosystem.
I like to think of this reality as a pyramid. Data integrity, the ultimate target outcome, is supported by an effectively operationalized data governance strategy. But that strategy is itself fully dependent on the mindset, behavior, and motivation of multiple personas that span a spectrum between data producers and data consumers – the “data culture” that produces and utilizes the data itself.
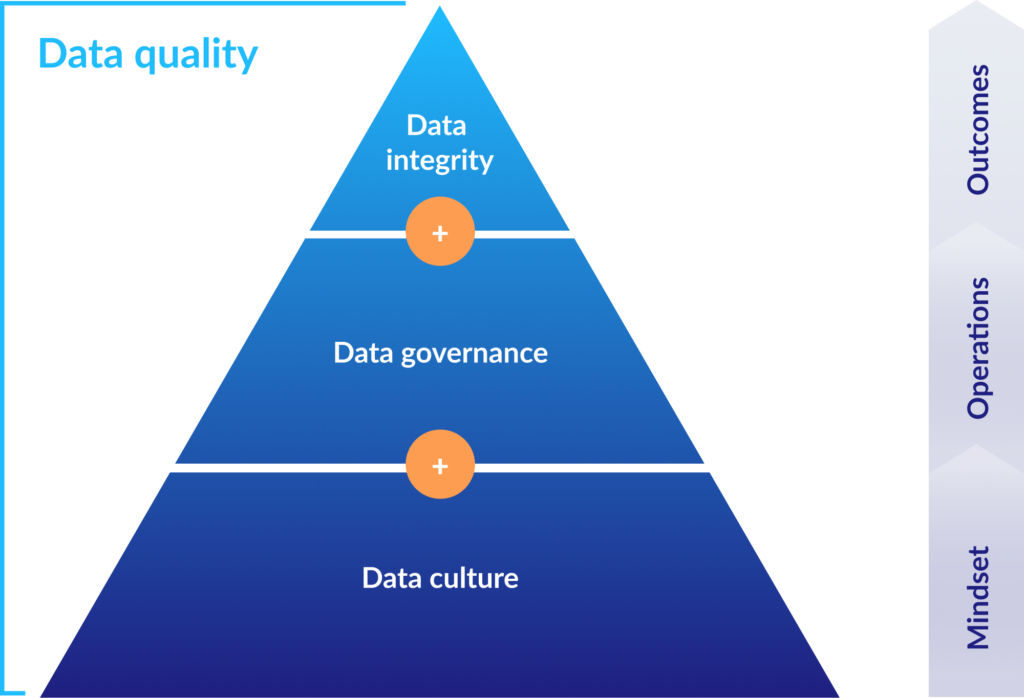
And as my colleague John Maguire discussed at the 2022 Digital CMC Summit, that culture takes time, dedication, and persistence to produce.
How can one be fostered at a drug development organization? It can be challenging in a business where organizational goals can have 10-year time horizons, and where data production and utilization tasks can often seem remote from the outcomes they support. But there are still many things data leaders and transformation stakeholders can do to encourage data-centric thinking and behaviors by the staff who have their hands on that data today.
Focus on a few key things:
- Policies: Set the rules for generating, logging, sharing, and referencing data. Make them clear and make them sticky.
- Ownership: Clearly define who’s responsible for critical assets like identifiers, taxonomies, and ontological metadata, and ensure that they know how and where those responsibilities fit into their day-to-day workflows.
- Processes: Establish clear steps for implementing and managing data infrastructure tasks, whether that’s recording experiment data in a FAIR format, atomizing document data appropriately, or generating reports in a way that complies with your data governance policies.
- Incentives: Ensure that data stakeholders feel like following data best practices will benefit them professionally, in whatever way makes sense for your business.
Each of these priorities can make a major contribution to a burgeoning data culture – by both setting clear expectations and showing the value of meeting them. Start there and focus there, and critical constructs like FAIR will take root in an organization that much more quickly and sustainably.
Coming up next: What structured data can mean for CMC processes and outputs
Strong data frameworks are all well and good, of course – but to borrow a phrase, every forward-thinking drug developer has a plan for their data until they get punched in the face by those exabytes of data. So what should a next-gen, truly data-savvy CMC program look like if it’s built with structured information in mind from the ground up?
Next up in our data governance series, we’ll get down to some of those brassier tacks with a closer look at what CMC workflows and outputs can look like when they’re built on a foundation of structured data.
Until then, check out some of our team’s other insights on evolving applications, challenges, and best practices for drug development data:
GET IN TOUCH
Ready to start structuring your product and process data?
No need to wait for the rest of our series. Reach out to our experts today to learn how we can help.


























































