
Co-authored by:

Yash Sabharwal
President & CEO, QbDVision

Paul Denny-Gouldson
Principal Consultant, Zifo RnD Solutions

Sujeegar Jeevanandam
Principal Consultant, Zifo RnD Solutions

John F. Conway
CVO, 20/15 Visioneers
Uniting perspectives & insights to explore the next frontier of CMC data
Having the opportunity to share my thoughts on key industry topics is always a pleasure for me. But while I love digging into favorite subjects like digital CMC and knowledge management, I know where my thinking benefits from expansion and amplification by experts with truly exceptional knowledge and perspective. And this is certainly one of them!
This in-depth post is a joint effort by myself and three of my very esteemed peers: Paul Denny-Gouldson, Ph. D, and Sujeegar Jeevanandum, both Principal Consultants at Zifo RnD Solutions, and John F. Conway, CVO at 20/15 Visioneers. I’m excited to share our collaborative thoughts on how FAIR data principles can help accelerate the nascent transformation of industry CMC programs, and where drug developers can begin applying this valuable framework to their CMC workflows.
As you’ll see, we believe the potential impact of this step will be a much-needed industry-wide shift: from siloed data producers and owners to true data innovators. Let’s look closer at why.
Snapshot:
- Life science organizations have discovered the immense value of their data, but many are still struggling to unlock the value of those assets.
- FAIR data principles can be the key, especially for CMC programs that currently produce and stockpile vast amounts of underutilized data outputs.
- To realize that upside, CMC programs will need to overcome several key organizational, behavioral, and technological barriers to adopting FAIR.
- A 3-step transition model developed by QbDVision can help jumpstart the shift from document-centric compliance to data-centric product and process development.
Life sciences companies are discovering the true value of their data – but many are still struggling to fully unlock it.
With digital transformation accelerating across the industry, pharma and biotech companies are now well aware that one of their most valuable assets isn’t a molecule or drug brand. It’s their petabytes of data.
These enormous proprietary information resources hold equally immense potential to drive their owner’s business performance. But while data flows from a panoply of different sources – clinical datasets, patient data, customer complaints, manufacturing systems, and more – they often face the same critical challenge. They’re produced, formatted, and stored in ways that leave them ill-prepared for accessibility and reuse.
To solve that challenge, and fully leverage this wealth of heterogeneous data, many organizations are starting to explore data management paradigms that can help them unify, harmonize, and amplify their vast information resources. The focus is increasingly on one framework in particular: FAIR.
Why life science innovators are focused on FAIR
Since their introduction nearly a decade ago, FAIR data principles have set a new gold standard for data stewardship and management across a number of industries. These principles provide actionable guidelines for how to make data assets findable, accessible, interoperable, and reusable (FAIR) to maximize their organizational value and promote data efficiency.
FIG 1: FAIR PRINCIPLES

Data can be easily searched and readily located thanks to rich, consistent metadata and globally unique, persistent identifiers.

(Meta)data have unique identifiers that enable them to be readily retrieved using a standardized communications protocol.

Data can be readily integrated with other properly formatted data through applications or workflows for analysis, storage, and processing.

(Meta)data should be well-described with numerous relevant and accurate attributes so they can be replicated and/or combined in different settings.
Adopting these principles is a potentially transformational opportunity for the life sciences, one that could fundamentally shift the industry away from its status quo of scattered, siloed, single-use-datasets, and toward a future of high-performance, data-driven drug development. Data-savvy industry thinkers are already investigating how FAIR principles can enhance a range of key workflows, including drug discovery, R&D, and clinical trials.
But what about the CMC workflows that generate so much essential drug development data?
CMC programs create some of the most important information resources in the drug development cycle, but also some of the most varied and diverse. For pharma and biotech organizations, this makes CMC workflows and data arguably one of the most important opportunities for the application of FAIR principles – but also one that faces particularly acute challenges to adoption.
“For drug development, FAIR is the gateway to digital transformation. It’s the framework our industry needs to evolve from data owners to data innovators.”
John F. Conway, CVO, 20/15 Visioneers
Embracing FAIR principles will be a watershed step in CMC data management.
Today, most CMC programs are still dependent on legacy technologies like MS Office and Adobe, which habitually leave valuable data buried in documents, folders, inboxes, and SharePoints. Facing tight development timelines and regulatory deadlines, opportunities to invest in better data governance are deprioritized in favor of clinical activities.
The result: unstructured, heterogeneous CMC datasets are often consigned to various folders on a fileserver, then manually compiled and summarized just in time for each regulatory submission. This unstructured, document-centric status quo keeps CMC on the critical path to regulatory submissions, stifles opportunities for process acceleration and risk mitigation, and hinders the accumulation of institutional knowledge and insight.
FIG 2: FAIR-IFIABLE CMC DATA DOMAINS
Where CMC programs can apply FAIR principles







With novel therapeutic modalities flooding the global pipeline and demanding a new generation of manufacturing processes, CMC teams are urgently in need of innovative strategies and digital frameworks for managing a “new normal” of unprecedented complexity. FAIR principles can be the answer, one that offers a consistent and robust data curation framework to enhance the efficiency of CMC workflows, proactively get CMC activities off the regulatory critical path, and scale the impact and velocity of each new program’s insights – all while building a wealth of organizational knowledge along the way.
The potential benefits for CMC programs are enormous. So what will it take to adopt them?
For CMC’s data champions, FAIR data principles pave the way to true program transformation – if they can break through some key adoption barriers.
For all the potential these principles may hold for CMC, the transition to FAIR-based data curation will face some significant challenges. The CMC function has a long legacy of document-centric workflows driven by built-for-purpose, single-use datasets shelved after one analysis. Multiple shifts need to happen for CMC programs to set a new FAIR standard for their stewardship of these potentially far more valuable data resources.
FIG 3: BARRIERS TO ADOPTING FAIR

BARRIER 1
Rethinking the ALCOA data integrity paradigm
To adopt a modern data framework like FAIR, CMC leaders will need to challenge the ALCOA paradigm that has kept them locked in a document-focused data integrity mindset for far too long.
The rules of ALCOA – Attributable, Legible, Contemporaneous, Original, and Accurate/Complete) – are inextricably linked to the static attributes of a document. Even with useful modernization updates like ALCOA+ and ALCOA++, this framework is still utterly outmatched by today’s vast and ever-increasing volumes of digital data. It’s time to recognize that ALCOA++ is not, in fact, a data integrity system – but rather an outcome of a strong data culture that promotes the integrity of its output.
An interesting analogue: health outcomes. While weight, blood pressure, cholesterol levels, and blood sugar are useful datapoints, these measurements are not a complete or predictive picture of a patient’s health. The behaviors that influence and produce these measurements – diet, exercise, sleep, stress levels – are typically far better indicators of long-term health.
CMC teams must make a similar shift in how they think about the production and curation of their data. Document-centric, procedural compliance leads to isolated information and static outputs – the BMI, LDL levels, and A1C counts of the CMC process. To overcome the limitations of this approach, CMC programs need to start developing a truly data-centric, behavioral mindset.
“Organizations need to recognize that ALCOA++ will not yield high data integrity. Instead, high data integrity is dependent on a strong data culture promoted by the FAIR framework, where the behavioral aspects of data management and usability will inherently produce the desired outcomes described by ALCOA++.”
Yash Sabharwal, President & CEO, QbDVision

BARRIER 2
Establishing clear incentives for data producers
Several changes in organizational culture and individual behavior also stand in the way of FAIR-ifying the CMC process. One of the most critical: a shift away from owning and using data for a limited purpose or specific analysis, and toward a mindset that data is part of an integrated, connected knowledge base that should be readily shareable and reusable.
In today’s CMC programs, individual contributors are typically focused on creating discrete outputs – experiments, analyses, reports, SOPs, etc – for specific applications. With reports due, submissions coming up, and other day-to-day pressures, these data producers are rarely encouraged to see how their outputs can connect to support bigger process, quality, or business initiatives – much less to change their behavior in ways that support those goals.
Incentivizing that shift is critically important to successful adoption of FAIR principles – guidelines that may seem counterintuitive and challenging to many managers and scientists. After all, FAIR asks them to shift the way they view one of the most fundamental products of their role: from an output “owned” by their team to a resource shared with and accessible to many other stakeholders.
The incentive to make this shift may vary, but it must be clear and meaningful for many stakeholders to change their behavior in a sustainable way.

BARRIER 3
Developing a unified CMC metadata ontology
To effectively implement FAIR principles, CMC programs need a clear, consistent, standardized, and domain-relevant labeling strategy that can be used to search, link, contextualize, and organize all of a program’s data.
This begs a vitally important question: how should metadata labels be constructed, and what labeling strategy should be used to maximize the organizational value of these datasets?
In today’s CMC data repositories, program metadata is almost universally attached to documents in quality management systems or empirical data from experiments. FAIR data principles promote broader structured relationships between data objects, which requires a substantive, domain-relevant data and metadata structure. Luckily, domain-relevant taxonomies and ontologies already exist in the form of ICH guidelines, quality-by-design concepts and principles, and cGMP.
These frameworks can be readily used to create a consistent, holistic architecture to describe and relate data such as:
- Product requirements and attributes
- Manufacturing process operations
- Process steps and variables
- Plant assets and materials
Each of these categories contains a range of well-defined objects that can be assigned relevant metadata and linked together to create a multi-dimensional, contextualized, and structured CMC dataset.

BARRIER 4
Updating legacy technology to enable Digital CMC
Rethinking ALCOA, incentivizing data producers, and domain relevant data architectures are all important steps in making FAIR feasible for a CMC program. But a critical facilitating factor is technology: these vital programs need modern digital solutions that enable them to build FAIR principles into every keystroke of their workflows.
Luckily, with the arrival of Digital CMC software like QbDVision, a data-centric workspace is finally available – one that unifies, structures, and connects expansive CMC data from the start.
So what does FAIR-ifying CMC data look like? This 3-step process shows how it begins.
At first glance, FAIR principles seem alluringly simple: “wouldn’t it be great if I could simply search for any data resource I need and immediately use it with other data?”
We’ve outlined the individual and organizational shifts in behavior to reach this ideal state. But, practically, the implementation of FAIR principles always presents the same core challenge: how do we translate static information resources into a format that’s findable, accessible, interoperable, and reusable?
At QbDVision, we’ve developed a 3-step process for achieving this transition. It effectively shifts CMC workflows from the “documents-as-databases” approach to a FAIR-based documentation paradigm that still retains the necessary compliance with ALCOA guidelines. The requirement for documentation doesn’t necessarily require a document!
FIG 4: 3 STEPS TO FAIR-IFY CMC DATA

Step 1: Atomize your data
Break your traditional document, report, or other unstructured narratives down into individual nodes of information categorized by categories like product (requirements and attributes), process (operational steps and variables), and plant (assets and materials).

Step 2: Assemble your data
Within each layer, assemble these nodes into a grouped structure based on industry-relevant taxonomies (e.g. ICH, QBD, GMP).
Step 3: Link your data
Build relationships between the nodes based on industry-relevant ontologies such as risk, process capability, and control strategy.
To see what this paradigm shift looks like in practice, let’s apply this process to an essential CMC document: a QTTP (Quality Target Product Profile).
“Adopting FAIR principles is an iterative, ongoing process. The view from at the beginning of this transition can be daunting. Life science organizations need a place to start, and for many, it starts with their documentation – breaking down those static information assets into smaller units of information and discovering how they can be transformed into rich, interconnected, insight-generating data.”
Paul Denny-Gouldson, Ph. D Principal Consultant, Zifo RnD Solutions

STEP 1
Break down the document (QTPP)
This document is a critical asset for any CMC team. It serves as a foundation for the development of drug manufacturing processes – so it’s also a document you may find that you frequently have to retrieve from SharePoint or inbox. Let’s see how it can be translated into a data resource that can be leveraged far more efficiently.
According to ICHQ8, a QTPP should provide a prospective summary of the drug product quality characteristics that ideally will be achieved to ensure the desired quality, taking into account safety and efficacy. Those will vary with many different factors, but common examples include both patient-related attributes (such as dosage form and administration route) and quality attributes (such as concentration, impurities, pH, and microbial limits).
FIG 5: ATOMIZING A QTTP
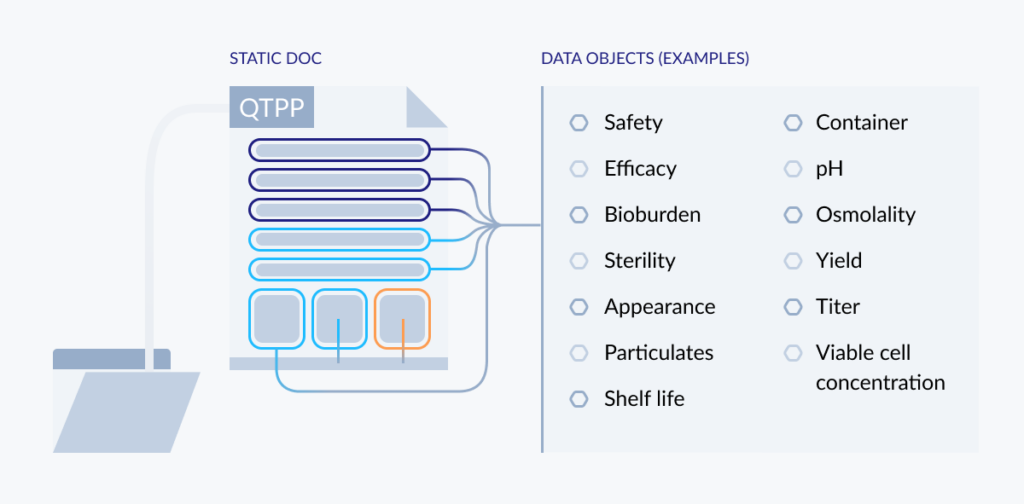
In a typical QTPP document, each of these characteristics appear as static, isolated entries. Using a FAIR approach, each of these characteristics becomes a unique object in the first layer of a multidimensional data structure. Let’s break them out so we can assign them their own properties, link them with other objects, and use them as the building blocks of that bigger structure.

STEP 2
Assemble QTPP data objects
Now that we’ve defined the basic objects in the QTPP, we can use them in many different ways. We can group them into categories, add linkable attributes and labels, and easily look for risk factors. Or, we can simply assemble them back into a QTPP for viewing, reporting, or collaboration!
FIG 6: ASSEMBLING QTTP DATA OBJECTS
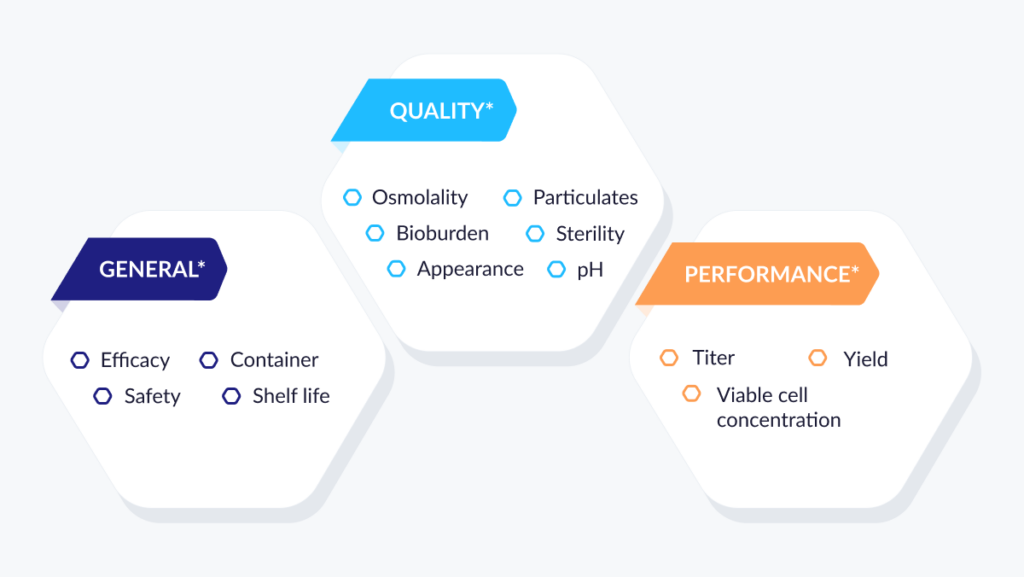
*Sample QTTP components only.

STEP 3
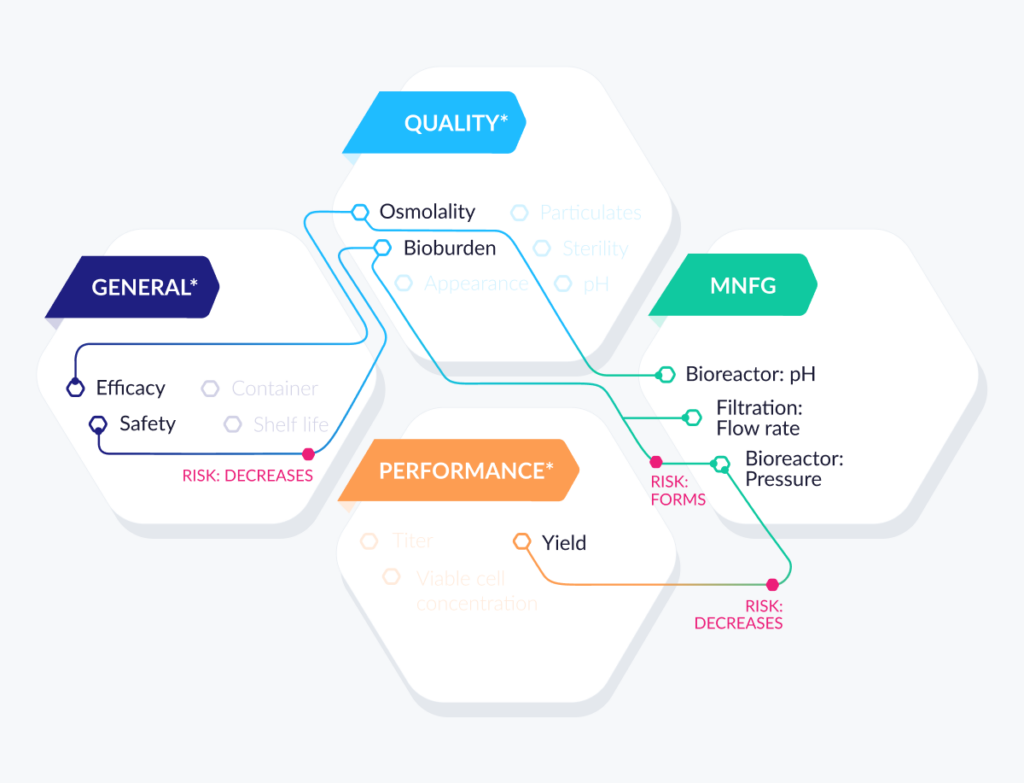
Link QTPP data objects
While steps 1 and 2 created the relevant taxonomies (labels and hierarchies) for the QTPP, the last step is to link these objects to form relationships between them – and thus create the relevant ontologies we need to create a true structured dataset.
FIG 6: LINKING QTTP DATA OBJECT7
*Sample QTTP components only.
For example, a product quality attribute in the QTPP can be linked to a process parameter based on the risk of that parameter to the quality attribute. That risk may then suggest the parameter has a significant impact on the quality attribute, resulting in the parameter being identified as critical. Similarly, that same quality attribute can be linked to a range of acceptable values that indicate how the attribute will be tested (e.g., an analytical method).
This capability to link objects and define the relationship between them is incredibly powerful, as it provides detailed context for each variable in a complex process. It also allows every data object to be easily identified within the structure, reused in multiple ways, and seamlessly incorporated into a software architecture that makes these operations as simple as a click.
Wondering where to start? Lucky for you, we’ve already figured it out.
For drug developers, adopting FAIR data principles is a vitally important step with enormous potential to amplify the value of CMC data and to drive overall CMC maturity. But it also requires some investment to accomplish effectively and sustainably.
Fortunately, a new ecosystem of purpose-built digital solutions is on the horizon. These solutions are already reimagining data management across CMC workflows – and in the case of QbDVision, FAIR principles are built into their DNA. The focus of this post has been on FAIR data, but there is an equally compelling case to be made for FAIR processes and how they complement FAIR data structures to advance overall CMC maturity. But that’s a conversation for another blog post.
With QbDVision, you can start implementing FAIR concepts (data and processes) today in your CMC program in the time it takes to install cloud software. QbDVision provides the structure, integration, and embedded workflows you need to build interconnected datasets in a secure virtual workspace – one that’s built for collaboration and automated compliance across the drug development cycle.
That’s one major adoption challenge solved, all in just a few clicks. We’re pretty sure your CMC specialists and engineers will love discovering how easy it is to manage their data in a structured environment that makes everything easy to search, trace, and analyze, all from one platform.
And those other steps? We did them for you too.
Want to see how QbDVision can help unlock the value of your CMC data? Get in touch, we’d love to show you.
Dive even deeper at the Digital CMC Summit.
Want to know where leading data gurus think drug development is headed? Join us live and in-person Nov 2-4, in Austin, TX!
About the authors
Yash Sabharwal, Ph.D., CEO & Co-Founder QbDVision
Yash is co-founder, President, and CEO,of CherryCircle Software. He is a successful serial entrepreneur. He has over 20 years of experience in the life science industry.
He was previously co-founder and Chief Operating Officer at Xeris Pharmaceuticals. It was in this role that he crafted the vision for CherryCircle Software and the development of the QbDVision platform.
Yash has a B.S. in Optics from the University of Rochester and a M.S. and Ph.D. in Optical Sciences from the University of Arizona.
Paul Denny-Gouldson, Ph. D, Principal Consultant, Zifo RnD Solutions
Paul has built up extensive experience in a broad range of scientific informatics and data management domains spanning research, development, manufacturing and clinical studies in Pharma/Biotech, FMCG, Chemical, Food & Bev and Oil & Gas organizations.
He has over twenty years of experience with global scientific informatics products, during which time he also founded several companies focused on combining science & technology. He started his career as a Post Doc and subsequently Senior Scientist at Sanofi-Synthelabo Toulouse (now Sanofi) for just under five years, where he managed a multidisciplinary molecular and cell biology group. Paul obtained his Ph.D. in Computational Biology from Essex University.
Sujeegar Jeevanandam, Principal Consultant, Zifo RnD Solutions
Sujeegar Jeevanandam (SJ) has over 12 years experience helping R & D functions in the Life Sciences domain to achieve excellence in scientific informatics. He has led Informatics Roadmap development & implementation programs for pharma and biotech organizations across the globe.
His current focus is on helping research organizations plan, kickstart and sustain the Digital Transformation journey.
John F. Conway, CVO, 20/15 Visioneers
John has spent over 30 years in R&D (Charles River, Orasure, AveCon Diagnostics (Co-Founded), Merck, GSK, and AstraZeneca) scientific software (Biovia and Schrodinger) and consulting (LabAnswer/Accenture). He is currently the Founder and Chief Visioneer Officer of 20/15 Visioneers, a Scientific and Technology Management Consulting and Marketing Services Company.

























































