
Data powers today’s leading businesses. But why not drug developers?
On the surface, industries like aerospace, mining, retail, and energy don’t appear to have much in common. But they all share one critical attribute: top businesses in every one of these sectors have learned how to turn their vast volumes of data into a powerful, performance-driving resource.
For many industries, “big data” is already old news. They’ve moved well beyond marveling at the scale of information they can generate, and started exploring innovative ways to plug their data generation engines straight back into their organizations – in the form of predictive algorithms, adaptive processes, AI-enabled workflows, and more.
But drug developers? Far too many of them are worried about where they’re going to store all those paper files. In an era defined by the power of data, drug developers are struggling to adapt, much less keep up.
And yet, there’s growing reason to believe they can, and will. Over the next few weeks we’ll explore why and how, with a new series on data governance, quality, and integrity in the drug development industry. Starting with this first chapter of our story, we’ll dig into the unique challenges facing pharma companies, biotech businesses, and their digital transformation, and the steps they can take to modernize their information infrastructure and achieve true digital maturity.
So let’s dive in, right at the root of the problem: unstructured data.
Standing on water: Data governance, integrity, and the challenge of unstructured data
Let’s start with some good news: in an era when “data is the new oil,” drug developers and manufacturers have drilled a well that would make Daniel Plainview blush. The ISPE “recently” reported that a single mid-sized biomanufacturing facility can generate anywhere from 0.5 to 10 petabytes of data every year – and that was in 2018. Just for reference, 1 petabyte is 4 times the content of the US Library of Congress.
But then there’s the bad news: there’s an enormous difference between tapping data and tapping its value. In fact, 70% of that continual data goes completely unused. For the most part, the life sciences’ information geyser delivers precious few valuable resources. Instead, it produces ever-expanding, nominally “managed” data slicks.
Why? Simple: to put a resource to use, it has to be in a usable form. The vast majority of drug development data isn’t, even as enormous volumes of it continue to be produced – only to be trapped in paper documents, PDFs, Microsoft files, and employees’ minds. No sooner is this data generated then it is marooned in these unstructured formats, only to be accessed with tedious, time-consuming, and all-too-frequently duplicated effort.
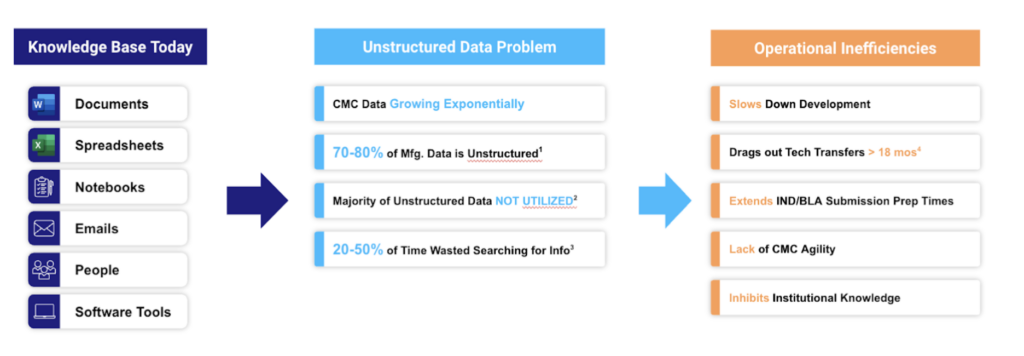
The impact of that challenge goes far beyond untapped organizational value or lost institutional knowledge.
Scattered, disconnected data sources can be impossibly hard to manage to regulatory standards like 21.CFR.11. Bridging islands in a fragmented, analog data ecosystem takes time – so much, in fact, that key data-sharing workflows like tech transfer now take 18 months or longer, on average. And drug developers awash in unstructured data often struggle to fully understand and articulate their own processes, much less how they need to be managed and controlled – leading to underpowered control strategies replete with unknown, unmitigated risks.
How big are those risks? We don’t want to name names, but just ask a pharma company that had their biosimilar rejected for the 3rd time because of data integrity issues. Or a beleaguered global CDMO whose recent control-related 483s have roiled customer product flow.
To put a resource to use, it has to be in a usable form. The vast majority of drug development isn’t, even as enormous volumes of it continue to be produced – only to be trapped in paper documents, PDFs, Microsoft files, and employees’ minds.
Yash Sabharwal, President & CEO, QbDVision
Just these two examples – along with many other recent ones – show how urgently drug developers and biomanufacturers need to evolve their policies and strategies for data governance. It’s never been more important for these businesses to establish a comprehensive approach to both generating and managing their data in ways that support effective, holistic data integrity – before they discover just how vulnerable their data ecosystems have become.
As we’ll see in this new series, developing that kind of approach is one of the smartest investments drug developers and manufacturers can make in their business – but it’s one that requires thoughtful planning, careful management, and serious commitment.
The first step, though, doesn’t start with the data itself. It starts with the mindset of the people creating it – and how businesses can help them escape one of the industry’s most common data integrity traps.
Squaring off with ALCOA+: Why it’s time to evolve industry’s legacy framework
To develop truly modern data governance methods, drug developers and manufacturers need to start with a fundamental principle: What constitutes “good” data management?
For decades now, the answer to that question has been simple: it means keeping data attributable, legible, contemporaneous, original, accurate, as well as complete, consistent, enduring, and available. It’s a framework that served the industry well at a time when information sources were limited and blockbuster small molecules stacked up new data in large but predictable batches.
Fast forward to an era of arcane biologic compounds, personalizable therapies, IoT-enabled manufacturing facilities, and sprawling global partner networks. Today, in an industry with vastly more, more complex, and more heterogeneous data to synthesize, the ALCOA framework is beyond brittle. When data is pouring in from countless sources, and needs to be leveraged across teams, facilities, and projects, who can limit “well-controlled data” to the latest time-stamped PDF with a legible signature?
ALCOA is a framework that served the industry well at a time when information sources were limited and blockbuster small molecules stacked up new data in large but predictable batches. But drug developers’ digital reality is now fundamentally different.
Kir Henrici, CEO, The Henrici Group
And yet, many drug developers and manufacturers are still struggling to break free from this document-centric mindset and imagine how ALCOA can evolve for a new era. The result: persistent friction and flaws in many drug development and manufacturing workflows. As famed FDA inspector Peter Baker observed recently, nearly 80% of recent CDER warning letters are the result of rigid adherence to ALCOA+ principles.
Shifting the assumed definition of effective data governance – moving it beyond instinctive alignment with ALCOA – will be the first mile of our industry’s long path to digital maturity. Today, many stakeholders still stand firm behind that framework, even as oceans of new data flood their servers and flow between siloes with little control.
Tomorrow’s data governance: What does the “right” structure look like?
Evolving our industry’s conception of “good” data management will be the catalyst for many transformative benefits – not the least of which will be lower risk of regulatory blowback. After all, well managed, consistently structured data is key to nearly every golden fleece in drug development: automated reporting and compliance, streamlined tech transfers, continuous manufacturing, and more.
There are two key dimensions of that structure, which we’ll delve into across this series:
- Where data is structured: Consolidating data resources in a single source of truth (SSOT) where it can be secured, integrated, and readily accessed in compliant ways – as well as prepared for use in more advanced applications.
- How data is structured: Generating and maintaining data in a properly labeled, easily usable format like FAIR (findable, accessible, interoperable, reusable) that enables any appropriate stakeholder to readily and efficiently leverage that resource.
Well managed, consistently structured data is key to nearly every golden fleece in drug development: automated reporting and compliance, streamlined tech transfers, continuous manufacturing, and more.
Peter Baker, President, Live Oak Quality Assurance
Both of these factors are crucial for pharma and biotech businesses that want to protect the quality and integrity of their drug development data. An effective SSOT transforms a core challenge of ALCOA+ – isolated, static documents as either the only or competing sources of truth – by creating canonical data records that can be accessed, linked, analyzed, and leveraged without a single compliance misstep. Using a framework like FAIR turns free data electrons – dispersed, disconnected, and chaotic – into a usable charge that can power many different applications.
Implementing either of those structures requires a robust data governance strategy that dictates how a business will generate, manage, and deploy its information resources. It also demands a clear methodology for how those policies and methods will be implemented – including how an organization will make the leap from document-centric compliance and quality control to data-focused efficiency and adaptability.
So what should those strategies and methods look like? That, dear reader, is for next time.
Coming up next: Laying the foundation of the data quality pyramid
So how do we get from here to there? How can drug developers lay the groundwork of data-centricity in their organizations, and ensure that their knowledge and information resources flow directly into usable structures – not unmanageable lakes?
In the next chapter of our series, we’ll explore what that process looks like for businesses that want to escape the gravitational pull of paper, paper-on-glass, and all their Adobe and Microsoft analogues. Stay tuned to find out where that process starts – with building an organizational data culture – and why that foundation is essential to strong data governance and consistent data integrity.
Until then, check out some of our team’s other insights on evolving applications, challenges, and best practices for drug development data:
GET IN TOUCH
Ready to start structuring your product and process data?
No need to wait for the rest of our series. Reach out to our experts today to learn how we can help.


























































